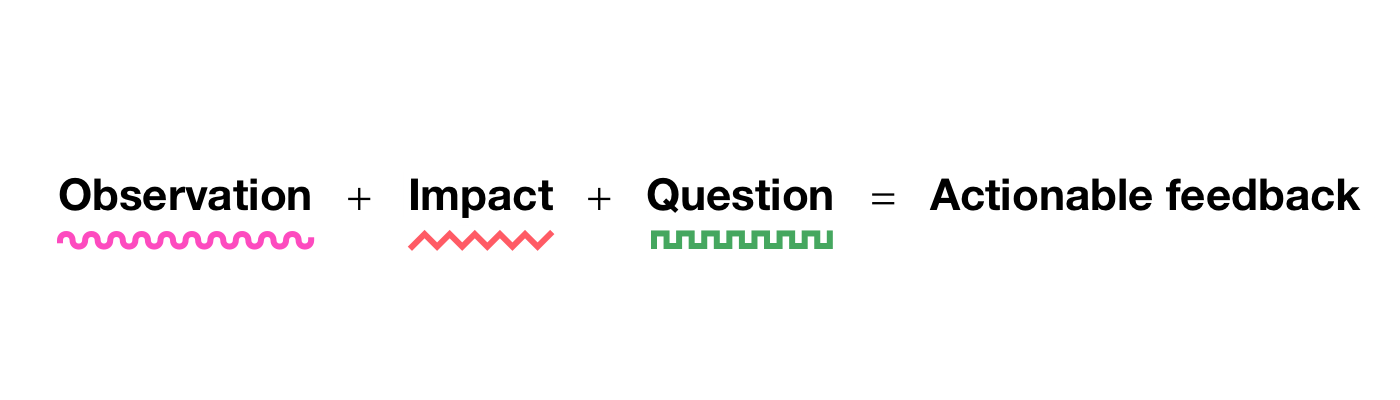
One of the most successful soft skills we have at our disposal is opinions, in whatever form it takes, and whatever it may be called. It helps us collaborate to improve our designs while developing our own abilities and perspectives.
Feedback is also one of the most underestimated equipment, and generally by assuming that we’re now great at it, we settle, forgetting that it’s a skill that can be trained, grown, and improved. Bad comments can lead to conflict on projects, lower confidence, and long-term, undermine trust and teamwork. Quality opinions can be a revolutionary force.
Practicing our knowledge is absolutely a good way to enhance, but the learning gets yet faster when it’s paired with a good base that programs and focuses the exercise. What are some fundamental components of providing effective opinions? And how can comments be adjusted for isolated and distributed job settings?
We can find a long history of sequential opinions on the web: code was written and discussed on mailing lists since the beginning of open source. Currently, engineers engage on pull calls, developers post in their favourite design tools, project managers and sprint masters exchange ideas on tickets, and so on.
Design analysis is often the label used for a type of input that’s provided to make our job better, jointly. It generally shares many of the concepts with suggestions, but it also has some differences.
The information
The content of the feedback is the basis of every effective criticism, so where do we need to begin? There are many versions that you can use to design your content. The one that I personally like best—because it’s obvious and actionable—is this one from Lara Hogan.
This calculation, which is typically used to provide feedback to users, even fits really well in a design critique because it finally addresses one of the main issues that we address: What? Where? Why? How? Imagine that you’re giving some comments about some pattern function that spans several screens, like an onboard movement: there are some pages shown, a stream blueprint, and an outline of the decisions made. You notice anything that needs to be improved. If you keep the three components of the equation in mind, you’ll have a mental unit that can help you become more precise and effective.
Here is a reply that could be included in some feedback, and it might appear fair at first glance because it appears to partially fulfill the requirements. But does it?
Not confident about the keys ‘ patterns and hierarchy—it feels off. Does you alter them?
Observation for style feedback doesn’t really mean pointing out which part of the software your input refers to, but it also refers to offering a viewpoint that’s as specific as possible. Do you offer the user’s viewpoint? Your expert perspective? A business perspective? From the perspective of the project manager? A first-time user’s perspective?
I anticipate that one of these two buttons will go forward and the other will go back when I see them.
Impact is about the why. Just pointing out a UI element might sometimes be enough if the issue may be obvious, but more often than not, you should add an explanation of what you’re pointing out.
I anticipate that one of these two buttons will go forward and the other will go back when I see them. But this is the only screen where this happens, as before we just used a single button and an “×” to close. This seems to be breaking the consistency in the flow.
The question approach is meant to provide open guidance by eliciting the critical thinking in the designer receiving the feedback. Notably, in Lara’s equation she provides a second approach: request, which instead provides guidance toward a specific solution. While that’s generally a viable option for feedback, I’ve found that going back to the question approach typically leads to the best solutions for design critiques because designers are generally more open to experiment in a space.
The difference between the two can be exemplified with, for the question approach:
I anticipate that one of these two buttons will go forward and the other will go back when I see them. But this is the only screen where this happens, as before we just used a single button and an “×” to close. This seems to be breaking the consistency in the flow. Would it make sense to unify them?
Or, for the request approach:
I anticipate that one of these two buttons will go forward and the other will go back when I see them. But this is the only screen where this happens, as before we just used a single button and an “×” to close. This seems to be breaking the consistency in the flow. Let’s make sure that all screens have the same pair of forward and back buttons.
At this point in some situations, it might be useful to integrate with an extra why: why you consider the given suggestion to be better.
I anticipate that one of these two buttons will go forward and the other will go back when I see them. But this is the only screen where this happens, as before we just used a single button and an “×” to close. This seems to be breaking the consistency in the flow. Let’s make sure that all screens have the same two forward and back buttons so that users don’t get confused.
Choosing the question approach or the request approach can also at times be a matter of personal preference. I did rounds of anonymous feedback and I reviewed feedback with other people a while back when I was putting a lot of effort into improving my feedback. After a few rounds of this work and a year later, I got a positive response: my feedback came across as effective and grounded. Until I changed teams. Quite unexpected, my next round of criticism from one particular person wasn’t very positive. The reason is that I had previously tried not to be prescriptive in my advice—because the people who I was previously working with preferred the open-ended question format over the request style of suggestions. However, there was a person in this other team who had always preferred specific guidance. So I adapted my feedback for them to include requests.
One comment that I heard come up a few times is that this kind of feedback is quite long, and it doesn’t seem very efficient. Yes, but also no. Let’s explore both sides.
No, this kind of feedback is effective because the length is a byproduct of clarity, and giving this kind of feedback can provide precisely enough information for a sound fix. Also if we zoom out, it can reduce future back-and-forth conversations and misunderstandings, improving the overall efficiency and effectiveness of collaboration beyond the single comment. Imagine that in the example above the feedback were instead just,” Let’s make sure that all screens have the same two forward and back buttons”. Since the designer receiving this feedback wouldn’t have much to go by, they might just implement the change. In later iterations, the interface might change or they might introduce new features—and maybe that change might not make sense anymore. The designer might assume that the change is about consistency without the explanation, but what if it wasn’t? So there could now be an underlying concern that changing the buttons would be perceived as a regression.
Yes, this style of feedback is not always efficient because the points in some comments don’t always need to be exhaustive, sometimes because certain changes may be obvious (” The font used doesn’t follow our guidelines” ) and sometimes because the team may have a lot of internal knowledge such that some of the whys may be implied.
Therefore, the equation above is intended to serve as a mnemonic to reflect and enhance the practice rather than a strict template for feedback. Even after years of active work on my critiques, I still from time to time go back to this formula and reflect on whether what I just wrote is effective.
The atmosphere
Well-grounded content is the foundation of feedback, but that’s not really enough. The soft skills of the person who’s providing the critique can multiply the likelihood that the feedback will be well received and understood. It has been demonstrated that only positive feedback can lead to sustained change in people, and tone alone can determine whether content is rejected or welcomed.
Since our goal is to be understood and to have a positive working environment, tone is essential to work on. I’ve tried to summarize the necessary soft skills over the years using a formula that resembles the one for content: the receptivity equation.
Respectful feedback comes across as grounded, solid, and constructive. It’s the kind of feedback that, whether it’s positive or negative, is perceived as useful and fair.
Timing refers to the moment when the feedback occurs. To-the-point feedback doesn’t have much hope of being well received if it’s given at the wrong time. When a new feature’s entire high-level information architecture is about to go on sale, it might still be relevant if the questioning raises a significant blocker that no one saw, but those concerns are much more likely to have to wait for a later revision. So in general, attune your feedback to the stage of the project. Early iteration? Iteration later? Polishing work in progress? Each of these needs varies. The right timing will make it more likely that your feedback will be well received.
Attitude is the equivalent of intent, and in the context of person-to-person feedback, it can be referred to as radical candor. Before writing, it’s important to make sure the person we’re writing will actually benefit them and improve the overall project. This might be a hard reflection at times because maybe we don’t want to admit that we don’t really appreciate that person. Hopefully that’s not the case, but it can happen, and that’s okay. Acknowledging and owning that can help you make up for that: how would I write if I really cared about them? How can I avoid being passive aggressive? How can I encourage constructive behavior?
Form is relevant especially in a diverse and cross-cultural work environments because having great content, perfect timing, and the right attitude might not come across if the way that we write creates misunderstandings. There could be many reasons for this, including the fact that occasionally certain words may cause specific reactions, that nonnative speakers may not be able to comprehend all thenuances of some sentences, that our brains may be different and that our world may be perceived differently; hence, neurodiversity must be taken into account. Whatever the reason, it’s important to review not just what we write but how.
A few years back, I was asking for some feedback on how I give feedback. I was given some sound advice, but I also got a surprise comment. They pointed out that when I wrote” Oh, ]… ]”, I made them feel stupid. That’s not what I meant to say! I felt really bad, and I just realized that I provided feedback to them for months, and every time I might have made them feel stupid. I was horrified … but also thankful. I quickly changed my situation by adding “oh” to my list of replaced words (your choice between aText, TextExpander, or others ) so that when I typed “oh,” it was immediately deleted.
Something to highlight because it’s quite frequent—especially in teams that have a strong group spirit—is that people tend to beat around the bush. It’s important to keep in mind that having a positive attitude doesn’t necessarily mean passing judgment on the feedback; rather, it simply means that you give it constructive and respectful feedback, whether it be difficult or positive. The nicest thing that you can do for someone is to help them grow.
We have a great advantage in giving feedback in written form: it can be reviewed by another person who isn’t directly involved, which can help to reduce or remove any bias that might be there. When I shared a comment with someone I knew,” How does this sound,”” How can I do it better,” or even” How would you have written it,” I discovered that the two versions had different meanings.
The format
Asynchronous feedback also has a significant inherent benefit: it allows us to spend more time making sure that the suggestions ‘ clarity and actionability meet two main objectives.
Let’s imagine that someone shared a design iteration for a project. You are reviewing it and leaving a comment. There are many ways to accomplish this, and context is of course important, but let’s try to think about some things that might be worthwhile to take into account.
In terms of clarity, start by grounding the critique that you’re about to give by providing context. This includes specifically describing where you’re coming from: do you have a thorough understanding of the project, or is this your first time seeing it? Are you coming from a high-level perspective, or are you figuring out the details? Are there regressions? Which user’s point of view are you addressing when offering feedback? Is the design iteration at a point where it would be okay to ship this, or are there major things that need to be addressed first?
Even if you’re giving feedback to a team that already has some project information, providing context is helpful. And context is absolutely essential when giving cross-team feedback. If I were to review a design that might be indirectly related to my work, and if I had no knowledge about how the project arrived at that point, I would say so, highlighting my take as external.
We frequently concentrate on the negatives and attempt to list all the things that could be improved. That’s of course important, but it’s just as important—if not more—to focus on the positives, especially if you saw progress from the previous iteration. Although this may seem superfluous, it’s important to keep in mind that design is a field with hundreds of possible solutions for each problem. So pointing out that the design solution that was chosen is good and explaining why it’s good has two major benefits: it confirms that the approach taken was solid, and it helps to ground your negative feedback. In the longer term, sharing positive feedback can help prevent regressions on things that are going well because those things will have been highlighted as important. Positive feedback can also help, as an added bonus, prevent impostor syndrome.
There’s one powerful approach that combines both context and a focus on the positives: frame how the design is better than the status quo ( compared to a previous iteration, competitors, or benchmarks ) and why, and then on that foundation, you can add what could be improved. This is powerful because there is a big difference between a critique of a design that is already in good shape and one that is critiqued for a design that isn’t quite there yet.
Another way that you can improve your feedback is to depersonalize the feedback: the comments should always be about the work, never about the person who made it. It’s” This button isn’t well aligned” versus” You haven’t aligned this button well”. This can be changed in your writing very quickly by reviewing it just before sending.
In terms of actionability, one of the best approaches to help the designer who’s reading through your feedback is to split it into bullet points or paragraphs, which are easier to review and analyze one by one. You might also consider breaking up the feedback into sections or even across multiple comments if it is longer. Of course, adding screenshots or signifying markers of the specific part of the interface you’re referring to can also be especially useful.
One approach that I’ve personally used effectively in some contexts is to enhance the bullet points with four markers using emojis. A red square indicates that it is something I consider blocking, a yellow diamond indicates that it needs to be changed, and a green circle provides a thorough, positive confirmation. I also use a blue spiral � � for either something that I’m not sure about, an exploration, an open alternative, or just a note. However, I’d only use this strategy on teams where I’ve already established a high level of trust because it might turn out to be quite demoralizing if I deliver a lot of red squares and change how I communicate that.
Let’s see how this would work by reusing the example that we used earlier as the first bullet point in this list:
- 🔶 Navigation—I anticipate that one of these two buttons will go forward and the other will go back when I see them. But this is the only screen where this happens, as before we just used a single button and an “×” to close. This seems to be breaking the consistency in the flow. Let’s make sure that all screens have the same two forward and back buttons so that users don’t get confused.
- � � Overall— I think the page is solid, and this is good enough to be our release candidate for a version 1.0.
- � � Metrics—Good improvement in the buttons on the metrics area, the improved contrast and new focus style make them more accessible.
- Button Style: Using the green accent in this context gives the impression that it’s a positive action because green is typically seen as a confirmation color. Do we need to explore a different color?
- Given the number of items on the page and the overall page hierarchy, it seems to me that the tiles should use Subtitle 2 instead of Subtitle 1. This will keep the visual hierarchy more consistent.
- � � Background—Using a light texture works well, but I wonder whether it adds too much noise in this kind of page. What is the purpose of using that?
What about giving feedback directly in Figma or another design tool that allows in-place feedback? These are generally difficult to use because they conceal discussions and are harder to follow, but in the right setting, they can be very effective. Just make sure that each of the comments is separate so that it’s easier to match each discussion to a single task, similar to the idea of splitting mentioned above.
One final note: say the obvious. Sometimes we might feel good or bad about something, so we don’t say it. Or sometimes we might have a doubt that we don’t express because the question might sound stupid. Say it, that’s fine. You might have to reword it a little bit to make the reader feel more comfortable, but don’t hold it back. Good feedback is transparent, even when it may be obvious.
Another benefit of asynchronous feedback is that written feedback automatically monitors decisions. Especially in large projects,” Why did we do this”? There’s nothing better than open, transparent discussions that can be reviewed at any time, and this could be a question that arises from time to time. For this reason, I recommend using software that saves these discussions, without hiding them once they are resolved.
Content, tone, and format. Although each of these subjects offers a useful model, improving eight of the subjects ‘ observation, impact, question, timing, attitude, form, clarity, and actionability is a lot of work to put in all at once. One effective approach is to take them one by one: first identify the area that you lack the most (either from your perspective or from feedback from others ) and start there. Then the second, followed by the third, and so on. At first you’ll have to put in extra time for every piece of feedback that you give, but after a while, it’ll become second nature, and your impact on the work will multiply.
Thanks to Brie Anne Demkiw and Mike Shelton for reviewing the first draft of this article.