How can a content management system ( CMS ) be set up to reach your current and future audience? I learned the hard way that creating a content model—a concept of information types, attributes, and relationships that let people and systems understand content—with my more comfortable design-system wondering would collapse my patient’s holistic information strategy. By developing conceptual information models that also connect related content, you can avoid that result.
A Fortune 500 company recently tapped me to guide the CMS application. The customer was excited by the benefits of an holistic information plan, including material modify, multichannel marketing, and robot delivery—designing content to be comprehensible to bots, Google knowledge panels, snippets, and voice user interfaces.
A content type is essential to an omnichannel content strategy, and it required conceptual types to be given names that don’t depend on how the content is presented. Our aim was to allow artists to create original content and use it where necessary. But as the job proceeded, I realized that supporting material utilize at the range that my client needed required the whole group to identify a new pattern.
Despite our best efforts, we remained influenced by pattern systems, which we were more comfortable with. An holistic content strategy cannot rely on WYSIWYG equipment for design and layout, unlike web-focused willing strategies. Our tendency to approach the material model with our common design-system thinking frequently led us to veer away from one of the main purposes of a material model: delivering content to audiences on various marketing channels.
Two fundamental tenets govern a successful content model
We needed to explain to our designers, developers, and stakeholders that we were undertaking a very different task from their earlier web projects, where it was common for everyone to view content as visual building blocks that fit into layouts. The previous approach was not only more familiar but also more intuitive—at least at first—because it made the designs feel more tangible. We discovered two guiding principles that helped the team understand how a content model and the design processes we were familiar with were:
- Instead of layout, semantics must be used by content models.
- And content models should connect content that belongs together.
Semantic content models
A semantic content model uses type and attribute names that reflect the content’s intended purpose and not its intended display. For example, in a nonsemantic model, teams might create types like teasers, media blocks, and cards. These types may make it simple to present content, but they do not aid in understanding the meaning of the content, which would have opened the door to the content presented in each marketing channel. In contrast, a semantic content model employs type names like product, service, and testimonial to allow for each delivery channel to interpret the content and use it as necessary.
When you’re creating a semantic content model, a great place to start is to look over the types and properties defined by Schema. a community-driven resource for type definitions that are understandable on platforms like Google search.
Benefits of a semantic content model include:
- Even if your team doesn’t care about omnichannel content, a semantic content model decouples content from its presentation so that teams can evolve the website’s design without needing to refactor its content. In this way, content can withstand irrational website redesigns.
- A semantic content model also gives you a competitive advantage. By adding structured data based on Schema. A website can provide hints to Google to understand the content, display it in search snippets or knowledge panels, and use it to respond to user voice-interface queries. Without ever visiting your website, potential visitors could easily find your content.
- Beyond those practical benefits, you’ll also need a semantic content model if you want to deliver omnichannel content. Delivery channels must be able to comprehend the same content in order to use it across multiple marketing channels. For instance, if your content model provided a list of questions and answers, it could be easily displayed on a frequently asked questions ( FAQ ) page as well as be used by a bot to answer frequently asked questions.
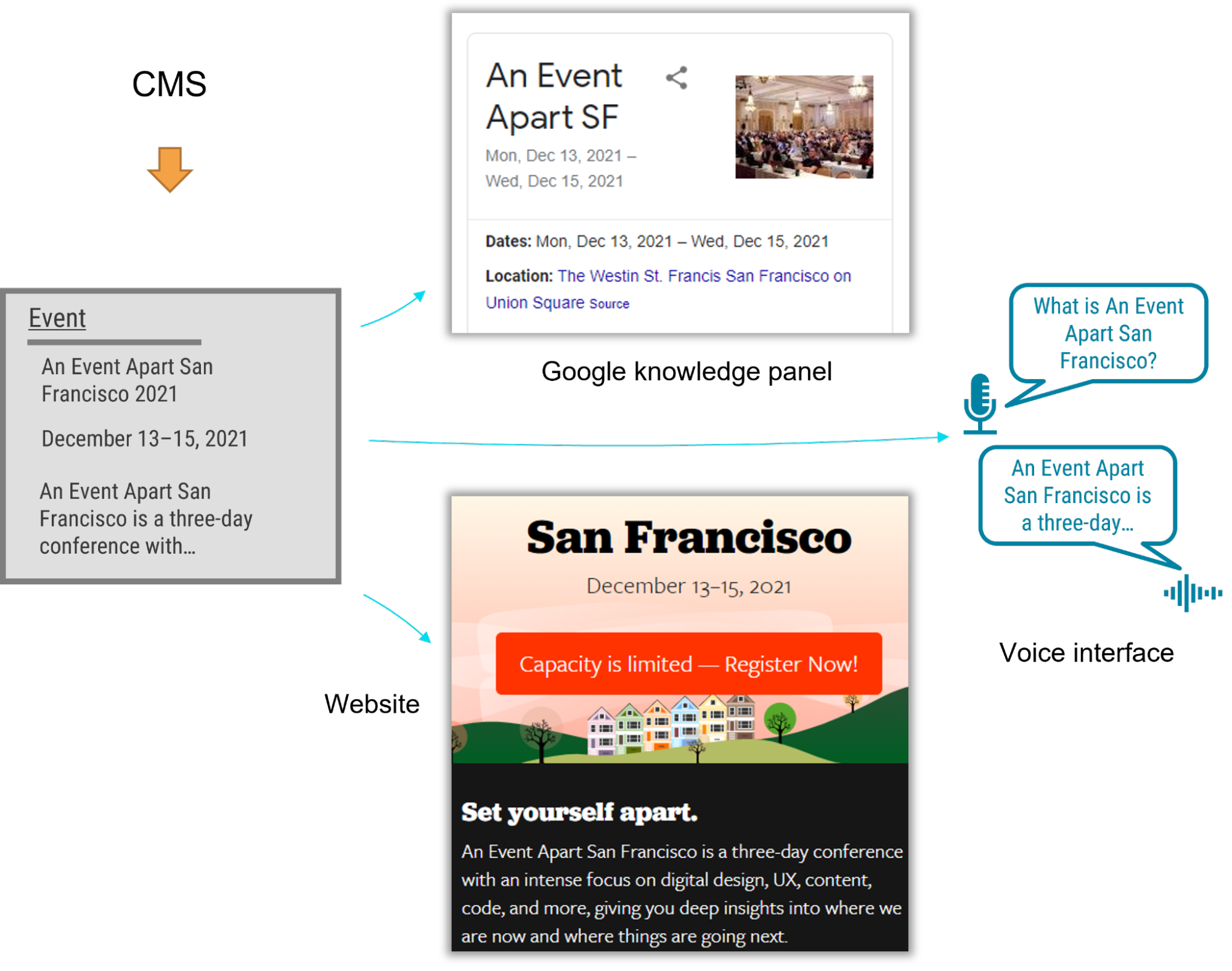
For example, using a semantic content model for articles, events, people, and locations lets A List Apart provide cleanly structured data for search engines so that users can read the content on the website, in Google knowledge panels, and even with hypothetical voice interfaces in the future.
connective content models
Instead of slicing up related content across disparate content components, I’ve come to the realization that the best models are those that are semantic and also connect related content components ( such as a FAQ item’s question and answer pair ). A good content model connects content that should remain together so that multiple delivery channels can use it without needing to first put those pieces back together.
Consider creating an essay or article. The meaning and usefulness of an article depend on how well its components are kept together. Would one of the headings or paragraphs be meaningful on their own without the context of the full article? Our well-known design-system thinking on our project frequently led us to want to develop content models that would divide content into distinct chunks to fit the web-centric layout. This had a similar effect to an article that had had its headline removed. Because we were slicing content into standalone pieces based on layout, content that belonged together became difficult to manage and nearly impossible for multiple delivery channels to understand.
Let’s take a look at how connecting related content works in a real-world setting to illustrate. A complex layout for a software product page that included multiple tabs and sections was presented by the client’s design team. Our instincts were to follow suit with the content model. Shouldn’t we make adding any number of tabs in the future as simple and flexible as possible?
We felt like we needed a content type called “tab section” because our design-system instincts were so well-known, so that multiple tab sections could be added to a page. Each tab section would display various types of content. The software’s overview or specifications might be available in one tab. A list of resources might be found under another tab.
Our inclination to break down the content model into “tab section” pieces would have led to an unnecessarily complex model and a cumbersome editing experience, and it would have also created content that couldn’t have been understood by additional delivery channels. How would a different system have been able to determine which “tab section” referred to a product’s specifications or resource list, for instance? Would that system have had to have used tab sections and content blocks to calculate these terms? This would have prevented the tabs from ever being rearranged, and it would have required adding logic to each other delivery channel to interpret the layout of the design system. Furthermore, if the customer were to have no longer wanted to display this content in a tab layout, it would have been tedious to migrate to a new content model to reflect the new page redesign.
Our customer had a breakthrough when we realized that each tab’s specific information, such as the software product’s overview, specifications, related resources, and pricing, was intended to reveal a specific purpose. Once implementation began, our inclination to focus on what’s visual and familiar had obscured the intent of the designs. It wasn’t long after a little digging that it became clear that the idea of tabs wasn’t applicable to the content model. What was important was the meaning of the information that they intended to display in the tabs.
In fact, the customer could have decided to display this content in a different way—without tabs—somewhere else. In response to this realization, we decided to create content types for the software product based on the meaningful qualities the client wanted to display on the web. There were both obvious semantic attributes like name and description and rich ones like screenshots, software requirements, and feature lists. The software’s product information stayed together because it wasn’t sliced across separate components like “tab sections” that were derived from the content’s presentation. This content could be understood and presented by any delivery channel, including those that come up in the future.
Conclusion
In this omnichannel marketing project, we discovered that the best way to keep our content model on track was to ensure that it was semantic ( with type and attribute names that reflected the meaning of the content ) and that it kept content together that belonged together ( instead of fragmenting it ). These two ideas made it easier for us to shape the content model based on the design. Remember: If you’re developing a content model to support an omnichannel content strategy, or even if you just want to make sure that Google and other interfaces understand your content, keep in mind:
- A design system isn’t a content model. You should maintain the semantic value and contextual structure of the content strategy throughout the entire implementation process because team members might be drawn to conflate them and force your content model to resemble your design system. Without the use of a magic decoder ring, every delivery channel will be able to consume the content.
- If your team is struggling to make this transition, you can still reap some of the benefits by using Schema. Your website uses structured data from org. The benefit of search engine optimization is a compelling reason on its own, even if additional delivery channels aren’t on the horizon in the near future.
- Additionally, remind the team that decoupling the content model from the design will let them update the designs more easily because they won’t be held back by the cost of content migrations. They will be prepared for the upcoming big thing, and they will be able to create new designs without compromising the compatibility between the content and the design.
By firmly defending these ideas, you’ll help your team view content as the most important component of your user experience and as the most effective way to engage with your audience.