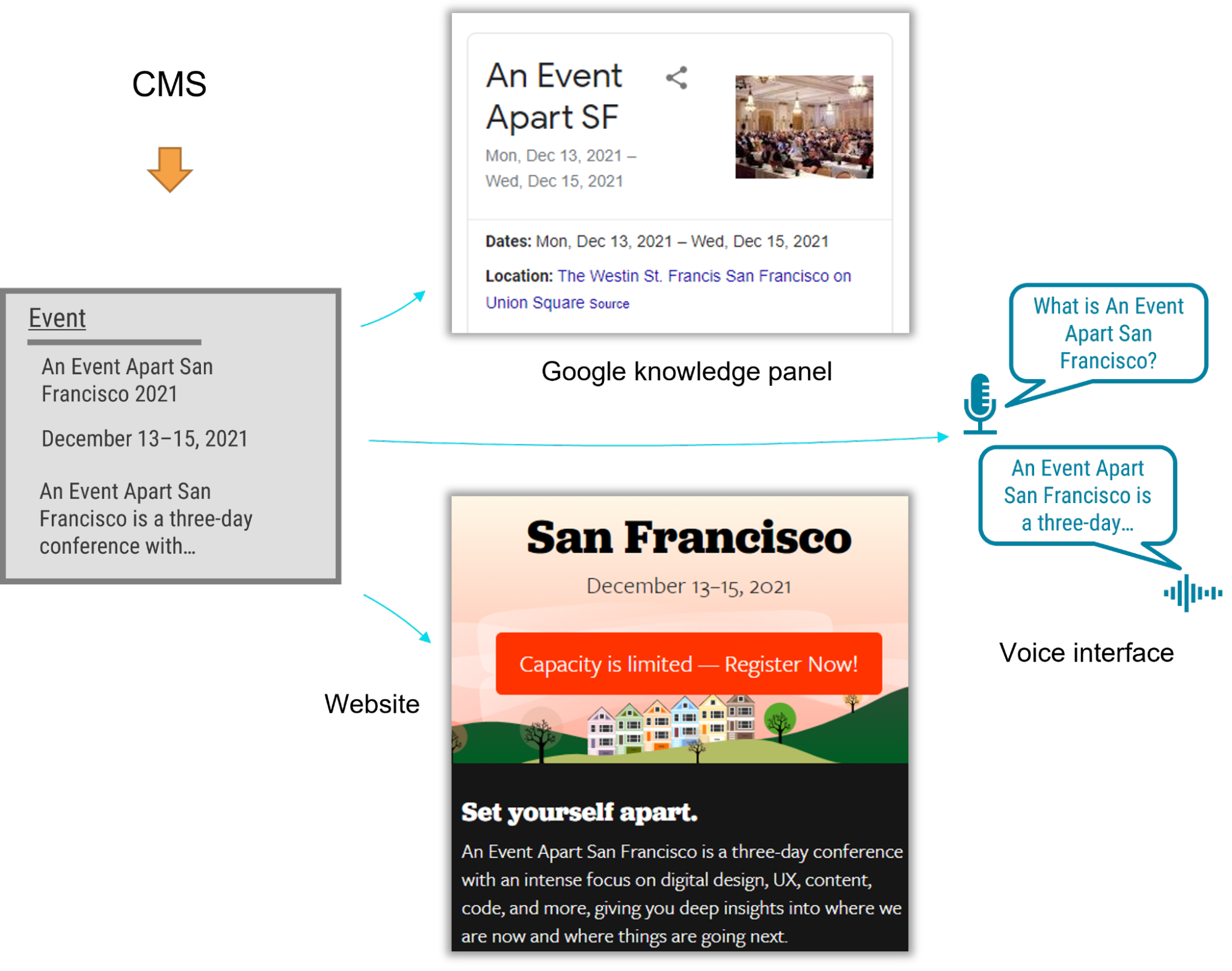
Although I’m not certain when I first heard this statement, it has stuck with me over the centuries. How do you generate solutions for scenarios you can’t think? Or create items that function on products that have not yet been created?
Flash, Photoshop, and flexible pattern
When I first started designing sites, my go-to technology was Photoshop. I created a design for a 960px paint that I would later add willing to. The growth phase was about attaining pixel-perfect reliability using set widths, fixed levels, and absolute placement.
All of this was altered by Ethan Marcotte’s speak at An Event Apart and the subsequent article in A Checklist Off in 2010. I was sold on responsive pattern as soon as I heard about it, but I was even terrified. The pixel-perfect models full of special figures that I had formerly prided myself on producing were no longer good enough.
My first encounter with flexible style didn’t help my fear. My second project was to get an active fixed-width website and make it reactive. I quickly realized that you didn’t just put responsiveness at the end of a job. To make smooth design, you need to prepare throughout the style stage.
A new way to style
Making information accessible to all devices a priority when designing responsive or liquid websites has always been the goal. It relies on the use of percentage-based design, which I immediately achieved with local CSS and power groups:
.column-span-6 { width: 49%; float: left; margin-right: 0.5%; margin-left: 0.5%;}.column-span-4 { width: 32%; float: left; margin-right: 0.5%; margin-left: 0.5%;}.column-span-3 { width: 24%; float: left; margin-right: 0.5%; margin-left: 0.5%;}
Therefore with Sass but that I could use @includes to re-use repeated blocks of code and transition to more semantic html:
.logo { @include colSpan(6);}.search { @include colSpan(3);}.social-share { @include colSpan(3);}
Media answers
The next ingredient for reactive design is press queries. Without them, regardless of whether the content remained readable, would shrink to fit the available space. ( The exact opposite issue developed with the introduction of a mobile-first approach. )
Media answers prevented this by allowing us to add breakpoints where the design could adapt. Like most people, I started out with three breakpoints: one for desktop, one for tablets, and one for mobile. Over the years, I added more and more for phablets, wide screens, and so on.
For years, I happily worked this way and improved both my design and front-end skills in the process. The only problem I encountered was making changes to content, since with our Sass grid system in place, there was no way for the site owners to add content without amending the markup—something a small business owner might struggle with. This is because each row in the grid was defined using a div as a container. Adding content meant creating new row markup, which requires a level of HTML knowledge.
String premium was a mainstay of early flexible design, present in all the frequently used systems like Bootstrap and Skeleton.
Another difficulty arose as I moved from a design firm building websites for little- to medium-sized companies, to larger in-house teams where I worked across a collection of related sites. In those positions, I began to work more frequently with washable parts.
Our rely on multimedia queries resulted in parts that were tied to frequent window sizes. If the goal of part libraries is modify, then this is a real problem because you can just use these components if the devices you’re designing for correspond to the viewport sizes used in the pattern library—in the process never really hitting that “devices that don’t already occur” goal.
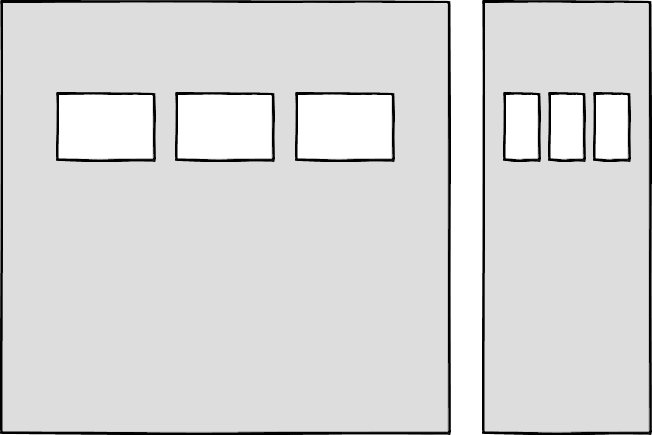
Then there’s the problem of space. Media answers allow components to adapt based on the viewport size, but what if I put a component into a sidebar, like in the figure below?
Container queries: our savior or a false dawn?
Container queries have long been touted as an improvement upon media queries, but at the time of writing are unsupported in most browsers. Workarounds for JavaScript exist, but they can lead to dependencies and compatibility issues. The basic theory underlying container queries is that elements should change based on the size of their parent container and not the viewport width, as seen in the following illustrations.
One of the biggest arguments in favor of container queries is that they help us create components or design patterns that are truly reusable because they can be picked up and placed anywhere in a layout. This is an important step in moving toward a form of component-based design that works at any size on any device.
In other words, responsive layouts are to be replaced by responsive components.
Container queries will help us move from designing pages that respond to the browser or device size to designing components that can be placed in a sidebar or in the main content, and respond accordingly.
My issue is that layout is still used to determine when a design needs to adapt. This approach will always be restrictive, as we will still need pre-defined breakpoints. For this reason, my main question with container queries is, How would we decide when to change the CSS used by a component?
The best place to make that choice is probably not a component library that is disconnected from context and real content.
As the diagrams below illustrate, we can use container queries to create designs for specific container widths, but what if I want to change the design based on the image size or ratio?
In this example, the dimensions of the container are not what should dictate the design, rather, the image is.
Without reliable cross-browser support for them, it’s difficult to say for certain whether container queries will be successful. Responsive component libraries would definitely evolve how we design and would improve the possibilities for reuse and design at scale. However, we might always need to modify these elements to fit our content.
CSS is changing
Whilst the container query debate rumbles on, there have been numerous advances in CSS that change the way we think about design. The days of fixed-width elements measured in pixels and floated div elements used to cobble layouts together are long gone, consigned to history along with table layouts. Flexbox and CSS Grid have revolutionized layouts for the web. We can now create elements that wrap onto new rows when they run out of space, not when the device changes.
.wrapper { display: grid; grid-template-columns: repeat(auto-fit, 450px); gap: 10px;}
The repeat() function paired with auto-fit or auto-fill allows us to specify how much space each column should use while leaving it up to the browser to decide when to spill the columns onto a new line. Similar things can be achieved with Flexbox, as elements can wrap over multiple rows and “flex” to fill available space.
.wrapper { display: flex; flex-wrap: wrap; justify-content: space-between;}.child { flex-basis: 32%; margin-bottom: 20px;}
You don’t need to wrap elements in container rows, which is the biggest benefit of all of this. Without rows, content isn’t tied to page markup in quite the same way, allowing for removals or additions of content without additional development.
This is a big step forward when it comes to creating designs that allow for evolving content, but the real game changer for flexible designs is CSS Subgrid.
Remember the days of crafting perfectly aligned interfaces, only for the customer to add an unbelievably long header almost as soon as they’re given CMS access, like the illustration below?
Subgrid allows elements to respond to adjustments in their own content and in the content of sibling elements, helping us create designs more resilient to change.
.wrapper { display: grid; grid-template-columns: repeat(auto-fit, minmax(150px, 1fr)); grid-template-rows: auto 1fr auto; gap: 10px;}.sub-grid { display: grid; grid-row: span 3; grid-template-rows: subgrid; /* sets rows to parent grid */}
CSS Grid allows us to separate layout and content, thereby enabling flexible designs. Meanwhile, Subgrid allows us to create designs that can adapt in order to suit morphing content. The above code can be implemented behind an @supports feature query even though Firefox is the only browser that supports subgrid at the time of writing.
Intrinsic layouts
I’d be remiss not to mention intrinsic layouts, a term used by Jen Simmons to describe a mix of contemporary and traditional CSS features used to create layouts that respond to available space.
Responsive layouts have flexible columns using percentages. Intrinsic layouts, on the other hand, use the fr unit to create flexible columns that won’t ever shrink so much that they render the content illegible.
frunits is a statement that says I want you to distribute the extra space in this manner, but never that it should be smaller than the content inside.
—Jen Simmons,” Designing Intrinsic Layouts”
Additionally, intrinsic layouts can mix and match both fixed and flexible units, letting the content choose how much space is taken up.
What makes intrinsic design stand out is that it not only creates designs that can withstand future devices but also helps scale design without losing flexibility. Without the requirement of having the same breakpoints or the same amount of content as in the previous implementation, components and patterns can be lifted and reused.
We can now create designs that adapt to the space they have, the content within them, and the content around them. We can create responsive components using an intrinsic approach without relying on container queries.
Another 2010 moment?
This intrinsic approach should in my view be every bit as groundbreaking as responsive web design was ten years ago. It’s another instance of “everything changed,” in my opinion.
But it doesn’t seem to be moving quite as fast, I haven’t yet had that same career-changing moment I had with responsive design, despite the widely shared and brilliant talk that brought it to my attention.
One possible explanation for that is that I now work for a sizable company, which is quite different from the design agency position I held in 2010. In my agency days, every new project was a clean slate, a chance to try something new. Nowadays, projects use existing tools and frameworks and are often improvements to existing websites with an existing codebase.
Another possibility is that right now I feel more prepared for change. In 2010 I was new to design in general, the shift was frightening and required a lot of learning. Additionally, an intrinsic approach isn’t exactly new; it’s about applying existing skills and CSS knowledge in a unique way.
You can’t framework your way out of a content problem
Another reason for the slightly slower adoption of intrinsic design could be the lack of quick-fix framework solutions available to kick-start the change.
Ten years ago, responsive grid systems were everywhere. With a framework like Bootstrap or Skeleton, you had a responsive design template at your fingertips.
Because the benefit of having a selection of units is a hindrance when it comes to creating layout templates, intrinsic design and frameworks do not go hand in hand quite as well. The beauty of intrinsic design is combining different units and experimenting with techniques to get the best for your content.
And then there are design tools. We probably all used Photoshop templates for desktop, tablet, and mobile devices to drop designs into and demonstrate how the site would look at all three stages at some point in our careers.
How do you do that now, with each component responding to content and layouts flexing as and when they need to? This kind of design must take place in the browser, which is something I’m very fond of.
The debate about “whether designers should code” is another that has rumbled on for years. When designing a digital product, we should, at the very least, design for a best- and worst-case scenario when it comes to content. It’s not ideal to implement this in a graphics-based software package. In code, we can add longer sentences, more radio buttons, and extra tabs, and watch in real time as the design adapts. Does it continue to function? Is the design too reliant on the current content?
Personally, I look forward to the day intrinsic design is the standard for design, when a design component can be truly flexible and adapt to both its space and content with no reliance on device or container dimensions.
Content should come first
Content is not constant. After all, to design for the unanticipated or unexpected, we must take into account changes in content, like in our earlier Subgrid card illustration, which allowed the cards to modify both their own content and that of their sibling components.
Thankfully, there’s more to CSS than layout, and plenty of properties and values can help us put content first. Subgrid and pseudo-elements like ::first-line and ::first-letter help to separate design from markup so we can create designs that allow for changes.
Instead of the dated markup tricks below,
First line of text with different styling...
—we can target content based on where it appears.
.element::first-line { font-size: 1.4em;}.element::first-letter { color: red;}
Much bigger additions to CSS include logical properties, which change the way we construct designs using logical dimensions (start and end) instead of physical ones (left and right), something CSS Grid also does with functions like min(), max(), and clamp().
This flexibility allows for directional changes according to content, a common requirement when we need to present content in multiple languages. In the past, this was often achieved with Sass mixins but was often limited to switching from left-to-right to right-to-left orientation.
Directional variables must be set in the Sass version.
$direction: rtl;$opposite-direction: ltr;$start-direction: right;$end-direction: left;
These variables can be used as values—
body { direction: $direction; text-align: $start-direction;}
—or as real estate.
margin-#{$end-direction}: 10px;padding-#{$start-direction}: 10px;
However, now we have native logical properties, removing the reliance on both Sass ( or a similar tool ) and pre-planning that necessitated using variables throughout a codebase. These properties also start to break apart the tight coupling between a design and strict physical dimensions, creating more flexibility for changes in language and in direction.
margin-block-end: 10px;padding-block-start: 10px;
There are also native start and end values for properties like text-align, which means we can replace text-align: right with text-align: start.
Like the earlier examples, these properties help to build out designs that aren’t constrained to one language, the design will reflect the content’s needs.
Fluid and fixed
We briefly covered the power of combining fixed widths with fluid widths with intrinsic layouts. The min() and max() functions are a similar concept, allowing you to specify a fixed value with a flexible alternative.
For min() this means setting a fluid minimum value and a maximum fixed value.
.element { width: min(50%, 300px);}
The element in the figure above will be 50 % of its container as long as the element’s width doesn’t exceed 300px.
For max() we can set a flexible max value and a minimum fixed value.
.element { width: max(50%, 300px);}
Now the element will be 50 % of its container as long as the element’s width is at least 300px. This means we can set limits but allow content to react to the available space.
The clamp() function builds on this by allowing us to set a preferred value with a third parameter. Now we can allow the element to shrink or grow if it needs to without getting to a point where it becomes unusable.
.element { width: clamp(300px, 50%, 600px);}
This time, the element’s width will be 50 % ( the preferred value ) of its container, with no exceptions for 300px and 600px.
With these techniques, we have a content-first approach to responsive design. We can separate content from markup, meaning the changes users make will not affect the design. By anticipating unforeseen language or direction changes, we can begin creating future-proofing designs. And we can increase flexibility by setting desired dimensions alongside flexible alternatives, allowing for more or less content to be displayed correctly.
First, the situation
Thanks to what we’ve discussed so far, we can cover device flexibility by changing our approach, designing around content and space instead of catering to devices. But what about that last bit of Jeffrey Zeldman’s quote,”… situations you haven’t imagined”?
It’s a lot different to design for someone using a mobile phone and walking through a crowded street in glaring sunshine than it is for someone using a desktop computer. Situations and environments are hard to plan for or predict because they change as people react to their own unique challenges and tasks.
Choice is so crucial because of this. One size never fits all, so we need to design for multiple scenarios to create equal experiences for all our users.
Thankfully, there is a lot we can do to provide choice.
Responsible design is important.
” There are parts of the world where mobile data is prohibitively expensive, and where there is little or no broadband infrastructure”.
” I Used the Web for a Day on a 50 MB Budget“
Chris Ashton
One of the biggest assumptions we make is that people interacting with our designs have a good wifi connection and a wide screen monitor. However, our users may be commuters using smaller mobile devices that may experience drops in connectivity while traveling on trains or other modes of transportation. There is nothing more frustrating than a web page that won’t load, but there are ways we can help users use less data or deal with sporadic connectivity.
The srcset attribute allows the browser to decide which image to serve. This means we can create smaller ‘cropped’ images to display on mobile devices in turn using less bandwidth and less data.

The preload attribute can also help us to think about how and when media is downloaded. It can be used to tell a browser about any critical assets that need to be downloaded with high priority, improving perceived performance and the user experience.
There’s also native lazy loading, which indicates assets that should only be downloaded when they are needed.

With srcset, preload, and lazy loading, we can start to tailor a user’s experience based on the situation they find themselves in. What none of this does, however, is allow the user themselves to decide what they want downloaded, as the decision is usually the browser’s to make.
So how can we put users in control?
The media queries are now being returned.
Media answers have always been about much more than device sizes. They allow content to adapt to different situations, with screen size being just one of them.
We’ve long been able to check for media types like print and speech and features such as hover, resolution, and color. These checks allow us to provide options that suit more than one scenario, it’s less about one-size-fits-all and more about serving adaptable content.
The Media Queries Level 5 spec is still being developed as of this writing. It introduces some really exciting queries that in the future will help us design for multiple other unexpected situations.
For instance, there is a light-level feature that enables you to alter a user’s style when they are in the sun or the darkness. Paired with custom properties, these features allow us to quickly create designs or themes for specific environments.
@media (light-level: normal) { --background-color: #fff; --text-color: #0b0c0c; }@media (light-level: dim) { --background-color: #efd226; --text-color: #0b0c0c;}
Another key feature of the Level 5 spec is personalization. Instead of creating designs that are the same for everyone, users can choose what works for them. This is achieved by using features like prefers-reduced-data, prefers-color-scheme, and prefers-reduced-motion, the latter two of which already enjoy broad browser support. These features tap into preferences set via the operating system or browser so people don’t have to spend time making each site they visit more usable.
Media answers like this go beyond choices made by a browser to grant more control to the user.
Expect the unexpected
In the end, the one thing we should always anticipate is that things will change. Devices in particular change faster than we can keep up, with foldable screens already on the market.
We can design for content, but we can’t do it the same way we do for this constantly changing landscape. By putting content first and allowing that content to adapt to whatever space surrounds it, we can create more robust, flexible designs that increase the longevity of our products.
A lot of the CSS discussed here is about moving away from layouts and putting content at the heart of design. There are still many more things we can do to adopt a more intrinsic approach, from responsive to fluid and fixed. Even better, we can test these techniques during the design phase by designing in-browser and watching how our designs adapt in real-time.
When it comes to unexpected circumstances, we need to make sure our goods are usable when people need them, whenever and wherever that may be. We can move closer to achieving this by involving users in our design decisions, by creating choice via browsers, and by giving control to our users with user-preference-based media queries.
Good design for the unexpected should allow for change, provide choice, and give control to those we serve: our users themselves.